아주 간단한 연락처 어플리케이션을 만들어 보자.
이 문제는 Trie라는 자료구조를 사용해서 푸는 문제이다. 사실 나는 Trie라는 자료구조를 이 문제를 통해 처음 알게 되었다. ‘트라이’ 라고 발음하는 것 같다. 역시 마찬가지로 간단하게 정리해 보자.
트라이(Trie):
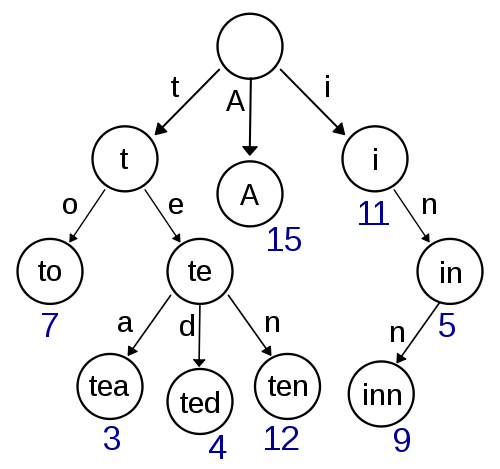
- n-차 트리
- 접두사 트리(prefix tree) 라고 부르기도 함
- 루트는 빈 노드
- 텍스트를 검색하는데 속도가 빠름
검색어 자동완성 기능에 이런 류의 자료 구조가 쓰이는 구나 싶었다.
문제는 두가지 요구사항이 있다.
- add name: name 부분으로 입력된 문자열을 입력한다.
- find partial: partial 부분으로 입력된 문자열로 시작하는 이름의 개수를 반환한다.
아래와 같이 풀어보았다.
| import java.io.*; | |
| import java.util.*; | |
| import java.text.*; | |
| import java.math.*; | |
| import java.util.regex.*; | |
| public class Solution { | |
| static class Trie { | |
| public int countChildWordNode = 0; | |
| public String value; | |
| public Trie [] nodeArray = new Trie[26]; | |
| } | |
| public static void main(String[] args) { | |
| Scanner in = new Scanner(System.in); | |
| int n = in.nextInt(); | |
| Trie root = new Trie(); | |
| for(int a0 = 0; a0 < n; a0++){ | |
| String op = in.next(); | |
| String contact = in.next(); | |
| if (op.equals("add")) { | |
| add(contact, root); | |
| } else if (op.equals("find")) { | |
| System.out.println(find(contact, root)); | |
| } | |
| } | |
| } | |
| public static void add(String name, Trie root) { | |
| for (int i = 0; i < name.length(); i++) { | |
| String value = name.substring(0, i+1); | |
| char[] charArray = value.toCharArray(); | |
| int length = charArray.length; | |
| int index = charArray[length-1] - 'a'; | |
| Trie newNode = root.nodeArray[index]; | |
| if (newNode == null) { | |
| newNode = new Trie(); | |
| newNode.value = value; | |
| } | |
| newNode.countChildWordNode++; | |
| root.nodeArray[index] = newNode; | |
| root = newNode; | |
| } | |
| } | |
| public static int find(String name, Trie root) { | |
| for (int i = 0; i < name.length(); i++) { | |
| String value = name.substring(0, i+1); | |
| char[] charArray = value.toCharArray(); | |
| int length = charArray.length; | |
| int index = charArray[length-1] - 'a'; | |
| Trie newNode = root.nodeArray[index]; | |
| if (newNode != null) { | |
| root = newNode; | |
| } else { | |
| return 0; | |
| } | |
| if (name.equals(root.value)) { | |
| return root.countChildWordNode; | |
| } | |
| } | |
| return 0; | |
| } | |
| } |
문제를 풀면서 꽤 애를 먹었다. 트라이 자체를 만들어 내는 것은 그렇게 어렵지 않았으나 자식노드의 수를 구하는 부분에서 어려움이 있었다. 처음엔 트리를 모두 순회하며 해당 문자열로 시작하는 노드의 수를 모두 세도록 만들었으나 몇몇 케이스에서 타임아웃에 걸렸다.
문제를 푸는 핵심 키는 문자열을 입력 할 때 마다 입력시 거쳐가는 노드의 자식 카운트를 하나씩 올려주는 것이다. 트라이 특성 상 자료 입력 시 글자 하나 마다 하나의 노드를 거쳐 가도록 되어있으므로 본인을 접두사로 포함하는 자식의 개수는 그냥 순회하는 노드마다 카운트를 1씩 올려주면 된다. 거쳐갔던 자료들의 수를 유지하고 있다면 “거쳐갔던 자료들의 수 = 노드의 값을 접두사로 포함하고 있는 노드의 개수” 가 된다.
예를들어 “abc”, “abcd”, “abcdefg” 는 공통적으로 “a” – “ab” – “abc”라는 노드를 거쳐서 저장되었다. 노드를 거쳐갈 때 마다 카운트를 1씩 올렸다면 “a”, “ab”, “abc” 노드는 세 번 거쳐갔을 것이므로 각각 3을 갖고있고(a와 ab는 실제로 입력된 자료가 아니지만 abc가 입력될때 abc가 거쳐가면서 생성됨) “abcd”는 2(abcd와 abcdefg가 거쳐감), “abcde”, “abcdef”, “abcdefg” 는 각각 1을 갖고 있을 것이다(a와 ab의 경우와 같이 abcdefg가 생성될 때 abcde, abcdef가 생성됨).
문제를 풀면서 새로운 자료구조를 배우고 또 고민고민끝에 해결책을 생각해 내 풀어내어서 굉장히 즐거웠던 문제였다!

댓글을 달려면 로그인해야 합니다.